Project 2: Web scrapping, data cleaning, data analysis, and data visualization on a portfolio website
1 Web Scraping, Data Analysis, and Visualization
1.1 Summary and highlight:
This project consisted in web scraping data from a porfolio website comprising of 110 papers. Consequently, we designed an algorithm to parse text-based information from each pages such as the abstract or title. In our data analysis, we used a natural language processing library to find the 100 most meaningful words for each publication webpage by omitting filler words (“and”, “for” etc). We also used the numpy and sklearn packages to one hot encode categorical data (top 100 most common words) and used the seaborn package to display the correlation between citation count and the 10 most words used.
1.2 Code:
import requests
from bs4 import BeautifulSoup, NavigableString, Tag
from bs4.dammit import EncodingDetector
import os
import pandas as pd
import httplib2
import json
from nltk.corpus import stopwords
import itertools
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import rcParams
from sklearn.linear_model import LinearRegression
def get_soup(url):
parser = 'html.parser'
resp = requests.get(url)
if 'charset' in resp.headers.get('content-type', '').lower():
http_encoding = resp.encoding
else:
http_encoding = None
html_encoding = EncodingDetector.find_declared_encoding(resp.content, is_html=True)
encoding = html_encoding or http_encoding
return BeautifulSoup(resp.content, parser, from_encoding=encoding)1.3 Q1 Summary: Data parsing
In this section, we parsed every single publication URL from the main webpage of a portfolio website. To do so, we found the URL subdirectories of every paper and concatenated each of them to the main webpage’s URL.
webpage = "https://community.dur.ac.uk/hubert.shum/comp42315/"
hrefs = get_soup(webpage).find_all('a', href=True)
for link in hrefs:
print("Link text: ", link.text, " link url: ", link["href"])
if link.text == "PUBLICATIONSto innovate":
url_publications_suffix = link["href"]
break## Link text: HOMEto discover link url: index.htm
## Link text: PUBLICATIONSto innovate link url: publicationfull_year_characteranimation.htmurl_publications = os.path.join(webpage, url_publications_suffix)
url_publications## 'https://community.dur.ac.uk/hubert.shum/comp42315/publicationfull_year_characteranimation.htm'def find_publication_topics(url_publications):
http = httplib2.Http()
response, content = http.request(url_publications)
url_list = []
for link in get_soup(url_publications).find_all('a', href=True):
if link["href"][:21]=="publicationfull_year_":
url_publications_suffix = link
url_publication_pages = os.path.join(webpage, link["href"])
url_list.append(url_publication_pages)
return url_list
url_topic_list = find_publication_topics(url_publications)
def get_paper_list_by_page(url):
soup = get_soup(url).find_all(href=True)
url_list = []
for item in soup:
ref = item['href']
if ref[:3]=="pbl":
url_list.append(os.path.join(webpage, ref))
return url_list
final_list_papers = []
for topic_url in url_topic_list:
url_publication_list_topic = get_paper_list_by_page(topic_url)
for paper in url_publication_list_topic:
if not paper in final_list_papers:
final_list_papers.append(paper)1.4 Q2 Summary: Extracting and storing text-based data in JSON
We accessed every URL link from every paper and extracted all the text-based information. We then proceeded by storing the data in a JSON file with keys corresponding to each different publication section.
def extract_text_from_url_page(url_page):
field_names = ["abstract", "authors", "bibtex", "ref1", "ref2", "meta0", "meta1", "meta2"]
output = {}
soup = get_soup(url_page).find_all("h1")
for item in soup:
output["title"] = item.text
break
soup = get_soup(url_page).find_all("p")
for field_name, item in zip(field_names, soup):
if field_name == "meta0" or field_name == "meta2":
break
if field_name == "authors":
output[field_name] = item.text.split("\r\n\t")[0]
else:
output[field_name] = item.text
return output
text_data_list = []
for ind, url in enumerate(final_list_papers):
print("\r{}/{}".format(ind, len(final_list_papers)), end="")
try:
text_data_list.append(extract_text_from_url_page(url_page = url))
except Exception as e:
print("Error found at: ", url)
print("Error: ", e)
#print(text_data_list)##
file_path = os.path.join(os.getcwd(), "data_file.json")
with open(file_path, "w") as f:
json.dump(text_data_list, f)
with open(file_path, "r") as f:
data_2 = json.load(f)
#print(data_2)1.5 Q3 Summary: Natural Language Processing and data cleaning
In this section, we found the 100 most common and meaningful words for the abstracts and titles of the 110 publications. To do so, we used the nltk.corpus module which removed every filler words.
stop_words = set(stopwords.words("english"))
def get_100_most_popular(key, ignore_words = []):
word_list = []
for item in text_data_list:
title = item[key]
words_title = title.replace("-", " ").lower().split()
for item in words_title:
if item in ignore_words:
continue
word_list.append(item)
word_popularity = {}
for word in word_list:
if not word in word_popularity:
word_popularity[word] = 1
else:
word_popularity[word] += 1
print(word_popularity)
sorted_words = sorted(word_popularity.items(), key=lambda x:x[1], reverse=True)[:100]
print(sorted_words)
words = [item[0] for item in sorted_words]
print(words)
return wordstitle_popular_words = get_100_most_popular(key="title", ignore_words = stop_words)
## [('based', 25), ('human', 17), ('using', 17), ('motion', 15), ('learning', 13), ('kinect', 12), ('multi', 9), ('data', 8), ('3d', 8), ('reconstruction', 8), ('network', 7), ('control', 7), ('deep', 7), ('recognition', 7), ('prediction', 6), ('aware', 6), ('depth', 6), ('real', 6), ('character', 6), ('interactions', 6), ('pose', 6), ('assessment', 6), ('shape', 6), ('rule', 6), ('temporal', 5), ('synthesis', 5), ('automatic', 5), ('simulating', 5), ('posture', 5), ('action', 5), ('environment', 5), ('graph', 5), ('reality', 5), ('via', 4), ('interaction', 4), ('framework', 4), ('animation', 4), ('system', 4), ('generation', 4), ('time', 4), ('channel', 4), ('analysis', 4), ('boxing', 4), ('occlusion', 4), ('object', 4), ('detection', 4), ('sparse', 4), ('hand', 4), ('fuzzy', 4), ('crowd', 4), ('recurrent', 3), ('class', 3), ('synthesizing', 3), ('relative', 3), ('emotion', 3), ('sign', 3), ('dance', 3), ('facial', 3), ('model', 3), ('multiple', 3), ('microsoft', 3), ('guided', 3), ('captured', 3), ('attention', 3), ('abnormal', 3), ('classification', 3), ('interactive', 3), ('conditions', 3), ('visualization', 3), ('car', 3), ('sketch', 3), ('imagery', 3), ('driving', 3), ('images', 3), ('saliency', 3), ('environments', 3), ('feature', 3), ('metric', 3), ('augmented', 3), ('face', 3), ('selection', 3), ('low', 3), ('base', 3), ('interpolation', 3), ('spatio', 2), ('manifold', 2), ('motions', 2), ('convolutional', 2), ('gan', 2), ('strength', 2), ('language', 2), ('information', 2), ('sensor', 2), ('dynamic', 2), ('gaussian', 2), ('driven', 2), ('inverse', 2), ('preparation', 2), ('behaviour', 2), ('movements', 2)]
## ['based', 'human', 'using', 'motion', 'learning', 'kinect', 'multi', 'data', '3d', 'reconstruction', 'network', 'control', 'deep', 'recognition', 'prediction', 'aware', 'depth', 'real', 'character', 'interactions', 'pose', 'assessment', 'shape', 'rule', 'temporal', 'synthesis', 'automatic', 'simulating', 'posture', 'action', 'environment', 'graph', 'reality', 'via', 'interaction', 'framework', 'animation', 'system', 'generation', 'time', 'channel', 'analysis', 'boxing', 'occlusion', 'object', 'detection', 'sparse', 'hand', 'fuzzy', 'crowd', 'recurrent', 'class', 'synthesizing', 'relative', 'emotion', 'sign', 'dance', 'facial', 'model', 'multiple', 'microsoft', 'guided', 'captured', 'attention', 'abnormal', 'classification', 'interactive', 'conditions', 'visualization', 'car', 'sketch', 'imagery', 'driving', 'images', 'saliency', 'environments', 'feature', 'metric', 'augmented', 'face', 'selection', 'low', 'base', 'interpolation', 'spatio', 'manifold', 'motions', 'convolutional', 'gan', 'strength', 'language', 'information', 'sensor', 'dynamic', 'gaussian', 'driven', 'inverse', 'preparation', 'behaviour', 'movements']#title_popular_wordsabstract_popular_words = get_100_most_popular(key="abstract", ignore_words = stop_words)
## [('motion', 132), ('propose', 106), ('based', 105), ('system', 85), ('method', 83), ('using', 80), ('real', 80), ('data', 73), ('human', 70), ('proposed', 69), ('new', 64), ('learning', 63), ('results', 62), ('time', 59), ('paper,', 56), ('features', 52), ('control', 51), ('different', 50), ('hand', 49), ('also', 47), ('show', 47), ('3d', 46), ('applications', 45), ('however,', 44), ('two', 44), ('existing', 40), ('motions', 39), ('framework', 39), ('body', 38), ('high', 38), ('applied', 36), ('network', 36), ('characters', 36), ('rule', 35), ('computer', 34), ('feature', 34), ('used', 34), ('joint', 34), ('algorithm', 34), ('use', 33), ('facial', 33), ('depth', 33), ('kinect', 33), ('methods', 32), ('information', 32), ('multiple', 32), ('due', 32), ('approach', 32), ('crowd', 32), ('experimental', 32), ('demonstrate', 31), ('performance', 31), ('virtual', 30), ('quality', 30), ('temporal', 29), ('effectively', 29), ('fuzzy', 29), ('deep', 28), ('model', 28), ('movement', 28), ('problem', 28), ('interactions', 27), ('graph', 26), ('interaction', 26), ('level', 26), ('local', 26), ('realistic', 25), ('database', 25), ('multi', 24), ('one', 24), ('character', 24), ('generate', 24), ('spatial', 23), ('work', 23), ('single', 23), ('images', 23), ('user', 23), ('environment', 23), ('optimal', 22), ('low', 22), ('training', 22), ('well', 22), ('animation', 22), ('dance', 22), ('evaluate', 22), ('shape', 22), ('pose', 22), ('without', 21), ('analysis', 21), ('postures', 21), ('captured', 21), ('world', 21), ('classification', 21), ('accuracy', 21), ('research', 20), ('large', 20), ('many', 20), ('capture', 20), ('complex', 20), ('novel', 20)]
## ['motion', 'propose', 'based', 'system', 'method', 'using', 'real', 'data', 'human', 'proposed', 'new', 'learning', 'results', 'time', 'paper,', 'features', 'control', 'different', 'hand', 'also', 'show', '3d', 'applications', 'however,', 'two', 'existing', 'motions', 'framework', 'body', 'high', 'applied', 'network', 'characters', 'rule', 'computer', 'feature', 'used', 'joint', 'algorithm', 'use', 'facial', 'depth', 'kinect', 'methods', 'information', 'multiple', 'due', 'approach', 'crowd', 'experimental', 'demonstrate', 'performance', 'virtual', 'quality', 'temporal', 'effectively', 'fuzzy', 'deep', 'model', 'movement', 'problem', 'interactions', 'graph', 'interaction', 'level', 'local', 'realistic', 'database', 'multi', 'one', 'character', 'generate', 'spatial', 'work', 'single', 'images', 'user', 'environment', 'optimal', 'low', 'training', 'well', 'animation', 'dance', 'evaluate', 'shape', 'pose', 'without', 'analysis', 'postures', 'captured', 'world', 'classification', 'accuracy', 'research', 'large', 'many', 'capture', 'complex', 'novel']#abstract_popular_words1.6 Q4 summary: Data cleaning and data visualization
In this section, we found the number of co-authors for the papers. Furthermore, we used the data visualisation seaborn package to show the display the results.
text_data_list[100]['authors']## 'Yuan Hu, Hubert P. H. Shum and Edmond S. L. Ho,'def split_authors(author_string):
number_of_authors = author_string.count(",")
if "and" in author_string:
number_of_authors += 1
if number_of_authors==1:
return [author_string[:-1]]
out = author_string[:-1].split(", ")
out = out[:-1] + out[-1].split(" and ")
return out
authors_formatted = []
for item in text_data_list:
authors_formatted.append(split_authors(item['authors']))
for item in authors_formatted:
print(item)## ['He Wang', 'Edmond S. L. Ho', 'Hubert P. H. Shum', 'Zhanxing Zhu']
## ['Qianhui Men', 'Edmond S. L. Ho', 'Hubert P. H. Shum', 'Howard Leung']
## ['Qianhui Men', 'Hubert P. H. Shum', 'Edmond S. L. Ho', 'Howard Leung']
## ['Jacky C. P. Chan', 'Hubert P. H. Shum', 'He Wang', 'Li Yi', 'Wei Wei', 'Edmond S. L. Ho']
## ['Naoya Iwamoto', 'Hubert P. H. Shum', 'Wakana Asahina', 'Shigeo Morishima']
## ['Naoya Iwamoto', 'Takuya Kato', 'Hubert P. H. Shum', 'Ryo Kakitsuka', 'Kenta Hara', 'Shigeo Morishima']
## ['Edmond S. L. Ho', 'Hubert P. H. Shum', 'He Wang', 'Li Yi']
## ['Wakana Asahina', 'Naoya Iwamoto', 'Hubert P. H. Shum', 'Shigeo Morishima']
## ['Yijun Shen', 'Jingtian Zhang', 'Longzhi Yang', 'Hubert P. H. Shum']
## ['Naoya Iwamoto', 'Hubert P. H. Shum', 'Longzhi Yang', 'Shigeo Morishima']
## ['Liuyang Zhou', 'Lifeng Shang', 'Hubert P. H. Shum', 'Howard Leung']
## ['Edmond S. L. Ho', 'Hubert P. H. Shum', 'Yiu-ming Cheung', 'P. C. Yuen']
## ['Hubert P. H. Shum', 'Ludovic Hoyet', 'Edmond S. L. Ho', 'Taku Komura', 'Franck Multon']
## ['Hubert P. H. Shum', 'Ludovic Hoyet', 'Edmond S. L. Ho', 'Taku Komura', 'Franck Multon']
## ['Hubert P. H. Shum', 'Taku Komura', 'Shuntaro Yamazaki']
## ['Hubert P. H. Shum', 'Edmond S. L. Ho']
## ['Taku Komura', 'Hubert P. H. Shum']
## ['Hubert P. H. Shum']
## ['Hubert P. H. Shum', 'Taku Komura', 'Pranjul Yadav']
## ['Hubert P. H. Shum', 'Taku Komura', 'Masashi Shiraishi', 'Shuntaro Yamazaki']
## ['Hubert P. H. Shum', 'Taku Komura', 'Shuntaro Yamazaki']
## ['Taku Komura', 'Hubert P. H. Shum', 'Edmond S. L. Ho']
## ['Hubert P. H. Shum', 'Taku Komura', 'Shuntaro Yamazaki']
## ['Hubert P. H. Shum', 'Taku Komura']
## ['Hubert P. H. Shum', 'Taku Komura']
## ['Manli Zhu', 'Qianhui Men', 'Edmond S. L. Ho', 'Howard Leung', 'Hubert P. H. Shum']
## ['Yijun Shen', 'Longzhi Yang', 'Edmond S. L. Ho', 'Hubert P. H. Shum']
## ['Kevin D. McCay', 'Edmond S. L. Ho', 'Hubert P. H. Shum', 'Gerhard Fehringer', 'Claire Marcroft', 'Nicholas Embleton']
## ['Jake Hall', 'Jacky C. P. Chan', 'Hubert P. H. Shum', 'Edmond S. L. Ho']
## ['Pierre Plantard', 'Hubert P. H. Shum', 'Franck Multon']
## ['Worasak Rueangsirarak', 'Jingtian Zhang', 'Nauman Aslam', 'Hubert P. H. Shum']
## ['Shanfeng Hu', 'Hindol Bhattacharya', 'Matangini Chattopadhyay', 'Nauman Aslam', 'Hubert P. H. Shum']
## ['Worasak Rueangsirarak', 'Kitchana Kaewkaen', 'Hubert P. H. Shum']
## ['Pierre Plantard', 'Hubert P. H. Shum', 'Anne-Sophie Le Pierres', 'Franck Multon']
## ['Yijun Shen', 'He Wang', 'Edmond S. L. Ho', 'Longzhi Yang', 'Hubert P. H. Shum']
## ['Pierre Plantard', 'Antoine Muller', 'Charles Pontonnier', 'Georges Dumont', 'Hubert P. H. Shum', 'Franck Multon']
## ['Pierre Plantard', 'Hubert P. H. Shum', 'Franck Multon']
## ['Hubert P. H. Shum', 'He Wang', 'Edmond S. L. Ho', 'Taku Komura']
## ['Pierre Plantard', 'Hubert P. H. Shum', 'Franck Multon']
## ['Hubert P. H. Shum', 'Taku Komura', 'Akinori Nagano']
## ['Qianhui Men', 'Howard Leung', 'Edmond S. L. Ho', 'Hubert P. H. Shum']
## ['Hubert P. H. Shum']
## ['Naoki Nozawa', 'Hubert P. H. Shum', 'Edmond S. L. Ho', 'Qi Feng']
## ['Li Li', 'Khalid N. Ismail', 'Hubert P. H. Shum', 'Toby P. Breckon']
## ['Qi Feng', 'Hubert P. H. Shum', 'Shigeo Morishima']
## ['Qi Feng', 'Hubert P. H. Shum', 'Shigeo Morishima']
## ['Naoki Nozawa', 'Hubert P. H. Shum', 'Edmond S. L. Ho', 'Shigeo Morishima']
## ['Naoki Nozawa', 'Hubert P. H. Shum', 'Edmond S. L. Ho', 'Shigeo Morishima']
## ['Jingtian Zhang', 'Hubert P. H. Shum', 'Kevin D. McCay', 'Edmond S. L. Ho']
## ['Pierre Plantard', 'Hubert P. H. Shum', 'Franck Multon']
## ['Zhiguang Liu', 'Liuyang Zhou', 'Howard Leung', 'Hubert P. H. Shum']
## ['Liuyang Zhou', 'Zhiguang Liu', 'Howard Leung', 'Hubert P. H. Shum']
## ['Hubert P. H. Shum', 'Edmond S. L. Ho', 'Yang Jiang', 'Shu Takagi']
## ['Kevin Mackay', 'Hubert P. H. Shum', 'Taku Komura']
## ['Jingtian Zhang', 'Hubert P. H. Shum', 'Jungong Han', 'Ling Shao']
## ['Yang Yang', 'Howard Leung', 'Hubert P. H. Shum', 'Jiao Li', 'Lanling Zeng', 'Nauman Aslam', 'Zhigeng Pan']
## ['Zheming Zuo', 'Daniel Organisciak', 'Hubert P. H. Shum', 'Longzhi Yang']
## ['Shanfeng Hu', 'Worasak Rueangsirarak', 'Maxime Bouchee', 'Nauman Aslam', 'Hubert P. H. Shum']
## ['Edmond S. L. Ho', 'Jacky C. P. Chan', 'Donald C. K. Chan', 'Hubert P. H. Shum', 'Yiu-ming Cheung', 'P. C. Yuen']
## ['Jingtian Zhang', 'Lining Zhang', 'Hubert P. H. Shum', 'Ling Shao']
## ['Meng Li', 'Howard Leung', 'Hubert P. H. Shum']
## ['Yang Yang', 'Huiwen Bian', 'Hubert P. H. Shum', 'Nauman Aslam', 'Lanling Zeng']
## ['Jeff K. T. Tang', 'Howard Leung', 'Taku Komura', 'Hubert P. H. Shum']
## ['Jeff K. T. Tang', 'Howard Leung', 'Taku Komura', 'Hubert P. H. Shum']
## ['Shanfeng Hu', 'Hubert P. H. Shum', 'Nauman Aslam', 'Frederick W. B. Li', 'Xiaohui Liang']
## ['Shanfeng Hu', 'Xiaohui Liang', 'Hubert P. H. Shum', 'Frederick W. B. Li', 'Nauman Aslam']
## ['Pengpeng Hu', 'Edmond S. L. Ho', 'Nauman Aslam', 'Taku Komura', 'Hubert P. H. Shum']
## ['Shanfeng Hu', 'Hubert P. H. Shum', 'Antonio Mucherino']
## ['Zhiying Leng', 'Jiaying Chen', 'Hubert P. H. Shum', 'Frederick W. B. Li', 'Xiaohui Liang']
## ['Kanglei Zhou', 'Jiaying Chen', 'Hubert P. H. Shum', 'Frederick W. B. Li', 'Xiaohui Liang']
## ['Qi Feng', 'Hubert P. H. Shum', 'Shigeo Morishima']
## ['Christopher Flinton', 'Philip Anderson', 'Hubert P. H. Shum', 'Edmond S. L. Ho']
## ['Edmond S. L. Ho', 'Kevin D. McCay', 'Hubert P. H. Shum', 'Longzhi Yang', 'David Sainsbury', 'Peter Hodgkinson']
## ['Qi Feng', 'Hubert P. H. Shum', 'Shigeo Morishima']
## ['Qi Feng', 'Hubert P. H. Shum', 'Shigeo Morishima']
## ['Hubert P. H. Shum', 'Taku Komura', 'Shu Takagi']
## ['Arindam Kar', 'Sourav Pramanik', 'Arghya Chakraborty', 'Debotosh Bhattacharjee', 'Edmond S. L. Ho', 'Hubert P. H. Shum']
## ['Asish Bera', 'Debotosh Bhattacharjee', 'Hubert P. H. Shum']
## ['Asish Bera', 'Ratnadeep Dey', 'Debotosh Bhattacharjee', 'Mita Nasipuri', 'Hubert P. H. Shum']
## ['Daniel Organisciak', 'Dimitrios Sakkos', 'Edmond S. L. Ho', 'Nauman Aslam', 'Hubert P. H. Shum']
## ['Munmun Bhattacharya', 'Sandip Roy', 'Kamlesh Mistry', 'Hubert P. H. Shum', 'Samiran Chattopadhyay']
## ['Lining Zhang', 'Hubert P. H. Shum', 'Li Liu', 'Guodong Guo', 'Ling Shao']
## ['Subhas Barman', 'Hubert P. H. Shum', 'Samiran Chattopadhyay', 'Debasis Samanta']
## ['Daniel Organisciak', 'Chirine Riachy', 'Nauman Aslam', 'Hubert P. H. Shum']
## ['Shanfeng Hu', 'Hubert P. H. Shum', 'Xiaohui Liang', 'Frederick W. B. Li', 'Nauman Aslam']
## ['Daniel Organisciak', 'Edmond S. L. Ho', 'Hubert P. H. Shum']
## ['Andreea Stef', 'Kaveen Perera', 'Hubert P. H. Shum', 'Edmond S. L. Ho']
## ['Qianhui Men', 'Hubert P. H. Shum']
## ['Ben Rainbow', 'Qianhui Men', 'Hubert P. H. Shum']
## ['John Hartley', 'Hubert P. H. Shum', 'Edmond S. L. Ho', 'He Wang', 'Subramanian Ramamoorthy']
## ['Yijun Shen', 'Joseph Henry', 'He Wang', 'Edmond S. L. Ho', 'Taku Komura', 'Hubert P. H. Shum']
## ['Shoujiang Xu', 'Edmond S. L. Ho', 'Nauman Aslam', 'Hubert P. H. Shum']
## ['Adam Barnett', 'Hubert P. H. Shum', 'Taku Komura']
## ['Joseph Henry', 'Hubert P. H. Shum', 'Taku Komura']
## ['Joseph Henry', 'Hubert P. H. Shum', 'Taku Komura']
## ['Muhammad Zeeshan Baig', 'Nauman Aslam', 'Hubert P. H. Shum']
## ['Muhammad Zeeshan Baig', 'Nauman Aslam', 'Hubert P. H. Shum', 'Li Zhang']
## ['Worasak Rueangsirarak', 'Chayuti Mekurai', 'Hubert P. H. Shum', 'Surapong Uttama', 'Roungsan Chaisricharoen', 'Kitchana Kaewkaen']
## ['Mohamed Omar', 'Alamgir Hossain', 'Li Zhang', 'Hubert P. H. Shum']
## ['Luca Crosato', 'Chongfeng Wei', 'Edmond S. L. Ho', 'Hubert P. H. Shum']
## ['Yuan Hu', 'Hubert P. H. Shum', 'Edmond S. L. Ho']
## ['Shoujiang Xu', 'Edmond S. L. Ho', 'Hubert P. H. Shum']
## ['Edmond S. L. Ho', 'Hubert P. H. Shum']
## ['Hubert P. H. Shum', 'Taku Komura', 'Takaaki Shiratori', 'Shu Takagi']
## ['Yao Tan', 'Hubert P. H. Shum', 'Fei Chao', 'V. Vijayakumar', 'Longzhi Yang']
## ['Lining Zhang', 'Hubert P. H. Shum', 'Ling Shao']
## ['Lining Zhang', 'Hubert P. H. Shum', 'Ling Shao']
## ['Jie Li', 'Hubert P. H. Shum', 'Xin Fu', 'Graham Sexton', 'Longzhi Yang']
## ['Yao Tan', 'Jie Li', 'Martin Wonders', 'Fei Chao', 'Hubert P. H. Shum', 'Longzhi Yang']
## ['Jie Li', 'Yanpeng Qu', 'Hubert P. H. Shum', 'Longzhi Yang']all_authors = np.unique(list(itertools.chain.from_iterable(authors_formatted)))
all_authors## array(['Adam Barnett', 'Akinori Nagano', 'Alamgir Hossain',
## 'Andreea Stef', 'Anne-Sophie Le Pierres', 'Antoine Muller',
## 'Antonio Mucherino', 'Arghya Chakraborty', 'Arindam Kar',
## 'Asish Bera', 'Ben Rainbow', 'Charles Pontonnier',
## 'Chayuti Mekurai', 'Chirine Riachy', 'Chongfeng Wei',
## 'Christopher Flinton', 'Claire Marcroft', 'Daniel Organisciak',
## 'David Sainsbury', 'Debasis Samanta', 'Debotosh Bhattacharjee',
## 'Dimitrios Sakkos', 'Donald C. K. Chan', 'Edmond S. L. Ho',
## 'Fei Chao', 'Franck Multon', 'Frederick W. B. Li',
## 'Georges Dumont', 'Gerhard Fehringer', 'Graham Sexton',
## 'Guodong Guo', 'He Wang', 'Hindol Bhattacharya', 'Howard Leung',
## 'Hubert P. H. Shum', 'Huiwen Bian', 'Jacky C. P. Chan',
## 'Jake Hall', 'Jeff K. T. Tang', 'Jiao Li', 'Jiaying Chen',
## 'Jie Li', 'Jingtian Zhang', 'John Hartley', 'Joseph Henry',
## 'Jungong Han', 'Kamlesh Mistry', 'Kanglei Zhou', 'Kaveen Perera',
## 'Kenta Hara', 'Kevin D. McCay', 'Kevin Mackay', 'Khalid N. Ismail',
## 'Kitchana Kaewkaen', 'Lanling Zeng', 'Li Li', 'Li Liu', 'Li Yi',
## 'Li Zhang', 'Lifeng Shang', 'Ling Shao', 'Lining Zhang',
## 'Liuyang Zhou', 'Longzhi Yang', 'Luca Crosato', 'Ludovic Hoyet',
## 'Manli Zhu', 'Martin Wonders', 'Masashi Shiraishi',
## 'Matangini Chattopadhyay', 'Maxime Bouchee', 'Meng Li',
## 'Mita Nasipuri', 'Mohamed Omar', 'Muhammad Zeeshan Baig',
## 'Munmun Bhattacharya', 'Naoki Nozawa', 'Naoya Iwamoto',
## 'Nauman Aslam', 'Nicholas Embleton', 'P. C. Yuen', 'Pengpeng Hu',
## 'Peter Hodgkinson', 'Philip Anderson', 'Pierre Plantard',
## 'Pranjul Yadav', 'Qi Feng', 'Qianhui Men', 'Ratnadeep Dey',
## 'Roungsan Chaisricharoen', 'Ryo Kakitsuka',
## 'Samiran Chattopadhyay', 'Sandip Roy', 'Shanfeng Hu',
## 'Shigeo Morishima', 'Shoujiang Xu', 'Shu Takagi',
## 'Shuntaro Yamazaki', 'Sourav Pramanik', 'Subhas Barman',
## 'Subramanian Ramamoorthy', 'Surapong Uttama', 'Takaaki Shiratori',
## 'Taku Komura', 'Takuya Kato', 'Toby P. Breckon', 'V. Vijayakumar',
## 'Wakana Asahina', 'Wei Wei', 'Worasak Rueangsirarak',
## 'Xiaohui Liang', 'Xin Fu', 'Yang Jiang', 'Yang Yang', 'Yanpeng Qu',
## 'Yao Tan', 'Yijun Shen', 'Yiu-ming Cheung', 'Yuan Hu',
## 'Zhanxing Zhu', 'Zheming Zuo', 'Zhigeng Pan', 'Zhiguang Liu',
## 'Zhiying Leng'], dtype='<U23')def count_copublications(author):
return np.sum([author in item for item in authors_formatted])
no_co_publications = np.array([count_copublications(author) for author in all_authors])
authors_sorted = all_authors[np.argsort(no_co_publications)][::-1]
publications_sorted = no_co_publications[np.argsort(no_co_publications)][::-1]no_co_publications## array([ 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1,
## 1, 1, 1, 1, 4, 1, 1, 3, 1, 1, 37, 2, 8,
## 5, 1, 1, 1, 1, 7, 1, 11, 110, 1, 3, 1, 2,
## 1, 2, 3, 5, 1, 3, 1, 1, 1, 1, 1, 3, 1,
## 1, 2, 2, 1, 1, 2, 2, 1, 5, 4, 3, 10, 1,
## 2, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 3, 4,
## 14, 1, 2, 1, 1, 1, 6, 1, 6, 6, 1, 1, 1,
## 2, 1, 6, 11, 2, 3, 4, 1, 1, 1, 1, 1, 23,
## 1, 1, 1, 2, 1, 4, 5, 1, 1, 2, 1, 2, 4,
## 2, 1, 1, 1, 1, 2, 1])np.argsort(no_co_publications)## array([ 0, 81, 79, 75, 73, 72, 71, 70, 69, 68, 67, 66, 64,
## 59, 56, 55, 52, 51, 49, 48, 82, 47, 83, 88, 121, 120,
## 119, 118, 114, 112, 111, 108, 106, 105, 104, 102, 101, 100, 99,
## 98, 92, 90, 89, 85, 46, 123, 12, 5, 7, 22, 13, 27,
## 28, 29, 30, 45, 32, 21, 4, 8, 35, 3, 19, 18, 43,
## 1, 14, 15, 16, 39, 11, 10, 37, 2, 6, 24, 9, 107,
## 91, 95, 74, 113, 115, 117, 40, 65, 53, 122, 80, 58, 57,
## 38, 54, 41, 50, 96, 36, 20, 76, 62, 44, 109, 116, 61,
## 97, 17, 77, 42, 60, 26, 110, 84, 86, 87, 93, 31, 25,
## 63, 33, 94, 78, 103, 23, 34])for author, number in zip(authors_sorted, publications_sorted):
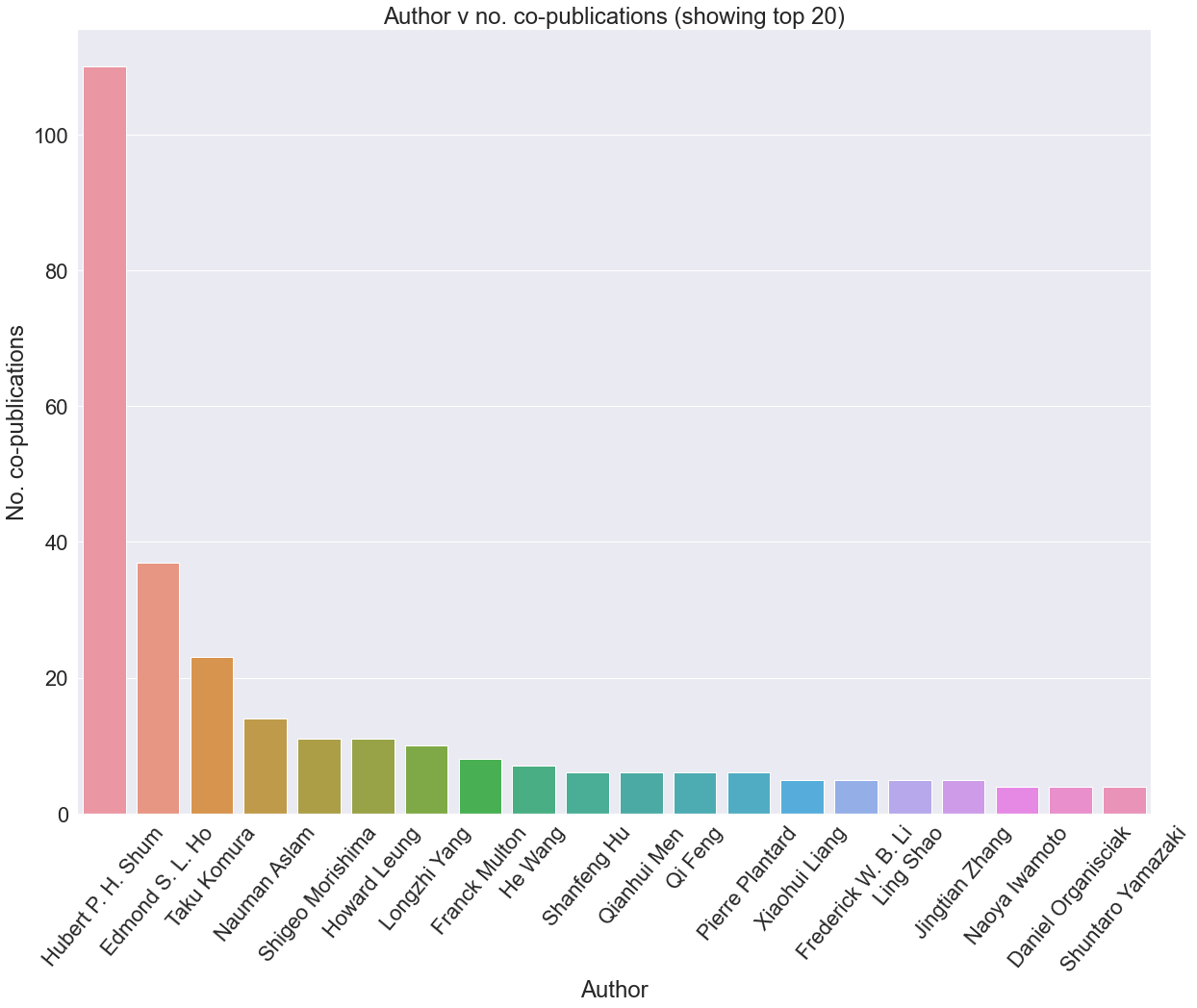
print("{}: {} co-publications".format(author, number))## Hubert P. H. Shum: 110 co-publications
## Edmond S. L. Ho: 37 co-publications
## Taku Komura: 23 co-publications
## Nauman Aslam: 14 co-publications
## Shigeo Morishima: 11 co-publications
## Howard Leung: 11 co-publications
## Longzhi Yang: 10 co-publications
## Franck Multon: 8 co-publications
## He Wang: 7 co-publications
## Shanfeng Hu: 6 co-publications
## Qianhui Men: 6 co-publications
## Qi Feng: 6 co-publications
## Pierre Plantard: 6 co-publications
## Xiaohui Liang: 5 co-publications
## Frederick W. B. Li: 5 co-publications
## Ling Shao: 5 co-publications
## Jingtian Zhang: 5 co-publications
## Naoya Iwamoto: 4 co-publications
## Daniel Organisciak: 4 co-publications
## Shuntaro Yamazaki: 4 co-publications
## Lining Zhang: 4 co-publications
## Yijun Shen: 4 co-publications
## Worasak Rueangsirarak: 4 co-publications
## Joseph Henry: 3 co-publications
## Liuyang Zhou: 3 co-publications
## Naoki Nozawa: 3 co-publications
## Debotosh Bhattacharjee: 3 co-publications
## Jacky C. P. Chan: 3 co-publications
## Shu Takagi: 3 co-publications
## Kevin D. McCay: 3 co-publications
## Jie Li: 3 co-publications
## Lanling Zeng: 2 co-publications
## Jeff K. T. Tang: 2 co-publications
## Li Yi: 2 co-publications
## Li Zhang: 2 co-publications
## P. C. Yuen: 2 co-publications
## Zhiguang Liu: 2 co-publications
## Kitchana Kaewkaen: 2 co-publications
## Ludovic Hoyet: 2 co-publications
## Jiaying Chen: 2 co-publications
## Yiu-ming Cheung: 2 co-publications
## Yao Tan: 2 co-publications
## Yang Yang: 2 co-publications
## Muhammad Zeeshan Baig: 2 co-publications
## Shoujiang Xu: 2 co-publications
## Samiran Chattopadhyay: 2 co-publications
## Wakana Asahina: 2 co-publications
## Asish Bera: 2 co-publications
## Fei Chao: 2 co-publications
## Antonio Mucherino: 1 co-publications
## Alamgir Hossain: 1 co-publications
## Jake Hall: 1 co-publications
## Ben Rainbow: 1 co-publications
## Charles Pontonnier: 1 co-publications
## Jiao Li: 1 co-publications
## Claire Marcroft: 1 co-publications
## Christopher Flinton: 1 co-publications
## Chongfeng Wei: 1 co-publications
## Akinori Nagano: 1 co-publications
## John Hartley: 1 co-publications
## David Sainsbury: 1 co-publications
## Debasis Samanta: 1 co-publications
## Andreea Stef: 1 co-publications
## Huiwen Bian: 1 co-publications
## Arindam Kar: 1 co-publications
## Anne-Sophie Le Pierres: 1 co-publications
## Dimitrios Sakkos: 1 co-publications
## Hindol Bhattacharya: 1 co-publications
## Jungong Han: 1 co-publications
## Guodong Guo: 1 co-publications
## Graham Sexton: 1 co-publications
## Gerhard Fehringer: 1 co-publications
## Georges Dumont: 1 co-publications
## Chirine Riachy: 1 co-publications
## Donald C. K. Chan: 1 co-publications
## Arghya Chakraborty: 1 co-publications
## Antoine Muller: 1 co-publications
## Chayuti Mekurai: 1 co-publications
## Zhiying Leng: 1 co-publications
## Kamlesh Mistry: 1 co-publications
## Pranjul Yadav: 1 co-publications
## Roungsan Chaisricharoen: 1 co-publications
## Ryo Kakitsuka: 1 co-publications
## Sandip Roy: 1 co-publications
## Sourav Pramanik: 1 co-publications
## Subhas Barman: 1 co-publications
## Subramanian Ramamoorthy: 1 co-publications
## Surapong Uttama: 1 co-publications
## Takaaki Shiratori: 1 co-publications
## Takuya Kato: 1 co-publications
## Toby P. Breckon: 1 co-publications
## V. Vijayakumar: 1 co-publications
## Wei Wei: 1 co-publications
## Xin Fu: 1 co-publications
## Yang Jiang: 1 co-publications
## Yanpeng Qu: 1 co-publications
## Yuan Hu: 1 co-publications
## Zhanxing Zhu: 1 co-publications
## Zheming Zuo: 1 co-publications
## Zhigeng Pan: 1 co-publications
## Ratnadeep Dey: 1 co-publications
## Philip Anderson: 1 co-publications
## Kanglei Zhou: 1 co-publications
## Peter Hodgkinson: 1 co-publications
## Kaveen Perera: 1 co-publications
## Kenta Hara: 1 co-publications
## Kevin Mackay: 1 co-publications
## Khalid N. Ismail: 1 co-publications
## Li Li: 1 co-publications
## Li Liu: 1 co-publications
## Lifeng Shang: 1 co-publications
## Luca Crosato: 1 co-publications
## Manli Zhu: 1 co-publications
## Martin Wonders: 1 co-publications
## Masashi Shiraishi: 1 co-publications
## Matangini Chattopadhyay: 1 co-publications
## Maxime Bouchee: 1 co-publications
## Meng Li: 1 co-publications
## Mita Nasipuri: 1 co-publications
## Mohamed Omar: 1 co-publications
## Munmun Bhattacharya: 1 co-publications
## Nicholas Embleton: 1 co-publications
## Pengpeng Hu: 1 co-publications
## Adam Barnett: 1 co-publicationslen(authors_sorted)## 124sns.set(font_scale=2)
limit = 20
sns.barplot(x=authors_sorted[:limit], y=publications_sorted[:limit], )
plt.xticks(rotation=50)## (array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
## 17, 18, 19]), [Text(0, 0, 'Hubert P. H. Shum'), Text(1, 0, 'Edmond S. L. Ho'), Text(2, 0, 'Taku Komura'), Text(3, 0, 'Nauman Aslam'), Text(4, 0, 'Shigeo Morishima'), Text(5, 0, 'Howard Leung'), Text(6, 0, 'Longzhi Yang'), Text(7, 0, 'Franck Multon'), Text(8, 0, 'He Wang'), Text(9, 0, 'Shanfeng Hu'), Text(10, 0, 'Qianhui Men'), Text(11, 0, 'Qi Feng'), Text(12, 0, 'Pierre Plantard'), Text(13, 0, 'Xiaohui Liang'), Text(14, 0, 'Frederick W. B. Li'), Text(15, 0, 'Ling Shao'), Text(16, 0, 'Jingtian Zhang'), Text(17, 0, 'Naoya Iwamoto'), Text(18, 0, 'Daniel Organisciak'), Text(19, 0, 'Shuntaro Yamazaki')])rcParams['figure.figsize'] = 20, 15
plt.ylabel("No. co-publications")
plt.xlabel("Author")
plt.title("Author v no. co-publications (showing top {})".format(limit))
1.7 Q5 summary: Data visualization and linear regression
In this section we found the relationship between citation count for the papers, and features such as:
- Number of co-authors
- Impact score
- Length of abstract
- Use of top 10 most common words in the abstract
paper = final_list_papers[0]
soup = get_soup(paper).findChild(class_="TextHighlightDefault")
cit_num = 0
for citation in soup:
if "impact" in citation.text.lower():
print(citation.text)
cit_num = float("".join([item for item in citation.text if item.isdigit() or item=="."]))
break## Impact Factor: 4.579cit_num## 4.579def get_citation_number(paper):
soup = get_soup(paper).findChild(class_="TextHighlightDefault")
cit_num = 0
for citation in soup:
if "citation" in citation.text.lower():
cit_num = int("".join([item for item in citation.text if item.isdigit()]))
break
return cit_num
def get_impact_factor(paper):
soup = get_soup(paper).findChild(class_="TextHighlightDefault")
num = 0
for citation in soup:
if "impact" in citation.text.lower():
num = float("".join([item for item in citation.text if item.isdigit() or item=="."]))
break
return num
final_list_citation = [get_citation_number(item) for item in final_list_papers]
final_list_impact = [get_impact_factor(item) for item in final_list_papers]
#for paper, cit_num, impact in zip(final_list_papers, final_list_citation, final_list_impact):
# print("paper: {} cit_num: {}, impact_factor: {}".format(paper, cit_num, impact))num_authors_list = [len(item) for item in authors_formatted]plt.hist(final_list_citation, bins=100)## (array([45., 9., 6., 8., 1., 4., 5., 0., 2., 6., 1., 0., 1.,
## 2., 3., 1., 0., 0., 0., 1., 1., 3., 0., 0., 1., 1.,
## 0., 0., 0., 1., 0., 1., 2., 0., 1., 0., 0., 1., 0.,
## 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
## 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.,
## 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
## 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
## 0., 0., 0., 0., 0., 0., 0., 0., 1.]), array([ 0. , 2.12, 4.24, 6.36, 8.48, 10.6 , 12.72, 14.84,
## 16.96, 19.08, 21.2 , 23.32, 25.44, 27.56, 29.68, 31.8 ,
## 33.92, 36.04, 38.16, 40.28, 42.4 , 44.52, 46.64, 48.76,
## 50.88, 53. , 55.12, 57.24, 59.36, 61.48, 63.6 , 65.72,
## 67.84, 69.96, 72.08, 74.2 , 76.32, 78.44, 80.56, 82.68,
## 84.8 , 86.92, 89.04, 91.16, 93.28, 95.4 , 97.52, 99.64,
## 101.76, 103.88, 106. , 108.12, 110.24, 112.36, 114.48, 116.6 ,
## 118.72, 120.84, 122.96, 125.08, 127.2 , 129.32, 131.44, 133.56,
## 135.68, 137.8 , 139.92, 142.04, 144.16, 146.28, 148.4 , 150.52,
## 152.64, 154.76, 156.88, 159. , 161.12, 163.24, 165.36, 167.48,
## 169.6 , 171.72, 173.84, 175.96, 178.08, 180.2 , 182.32, 184.44,
## 186.56, 188.68, 190.8 , 192.92, 195.04, 197.16, 199.28, 201.4 ,
## 203.52, 205.64, 207.76, 209.88, 212. ]), <BarContainer object of 100 artists>)plt.ylabel("Num. papers")
plt.xlabel("Num. citations")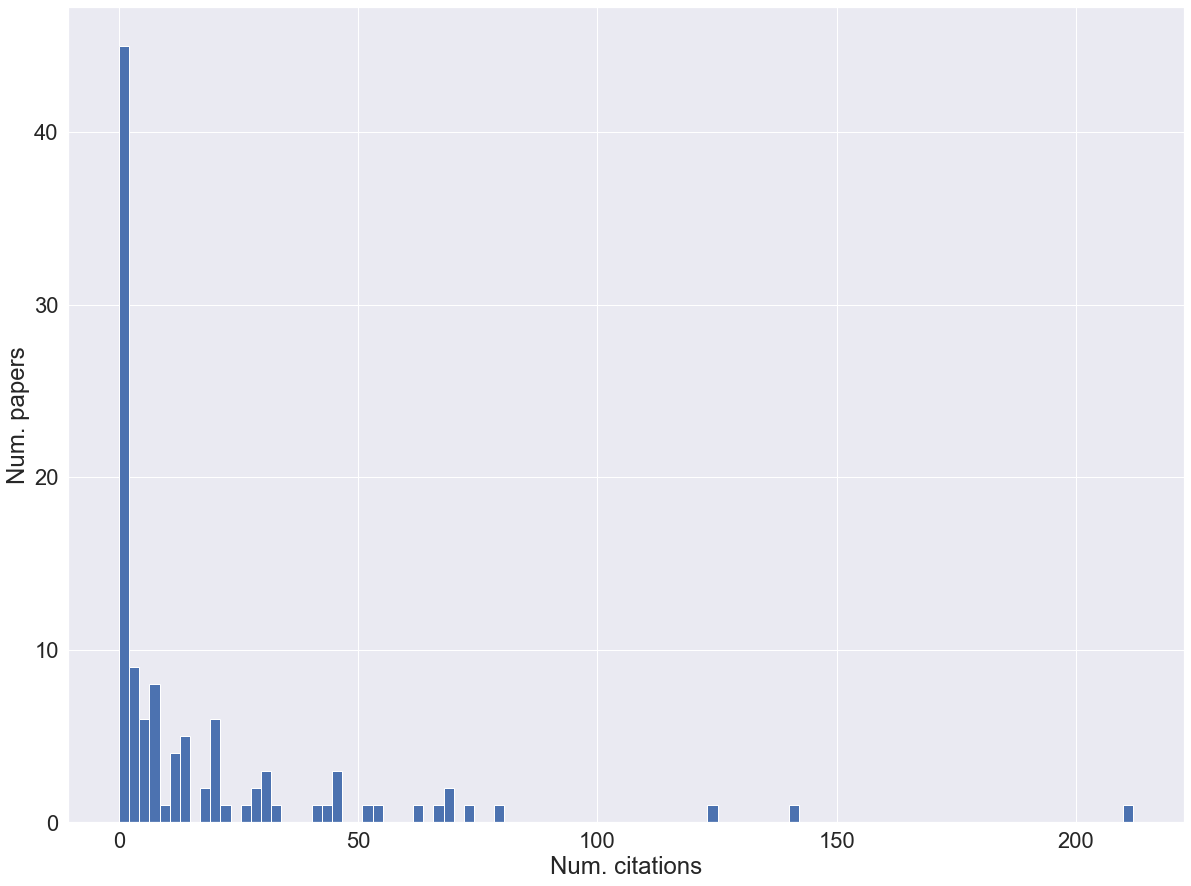
plt.hist(num_authors_list, bins=6)## (array([ 2., 6., 31., 40., 20., 11.]), array([1., 2., 3., 4., 5., 6., 7.]), <BarContainer object of 6 artists>)plt.ylabel("Num. papers")
plt.xlabel("Num. co-authors")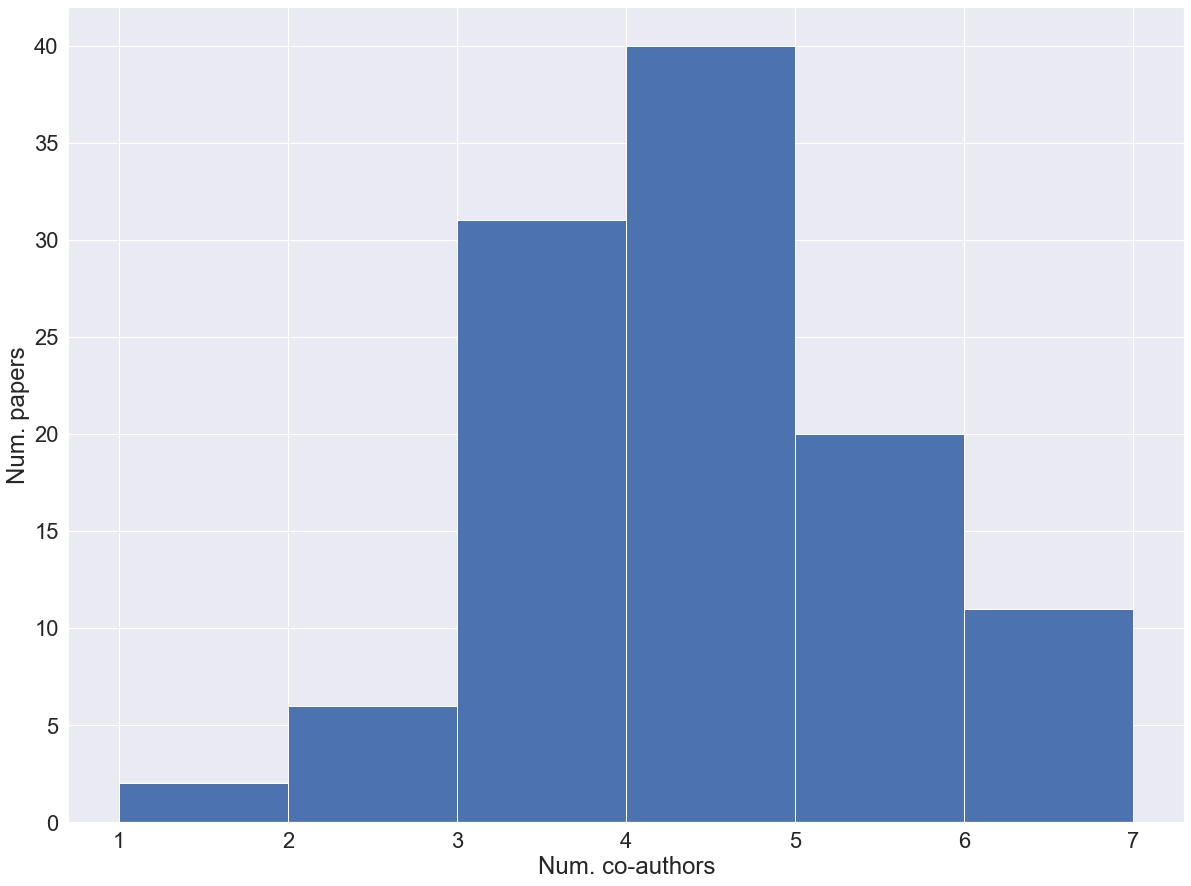
sns.scatterplot(num_authors_list, final_list_citation)
plt.ylabel("Num. citations")
plt.xlabel("Num. authors")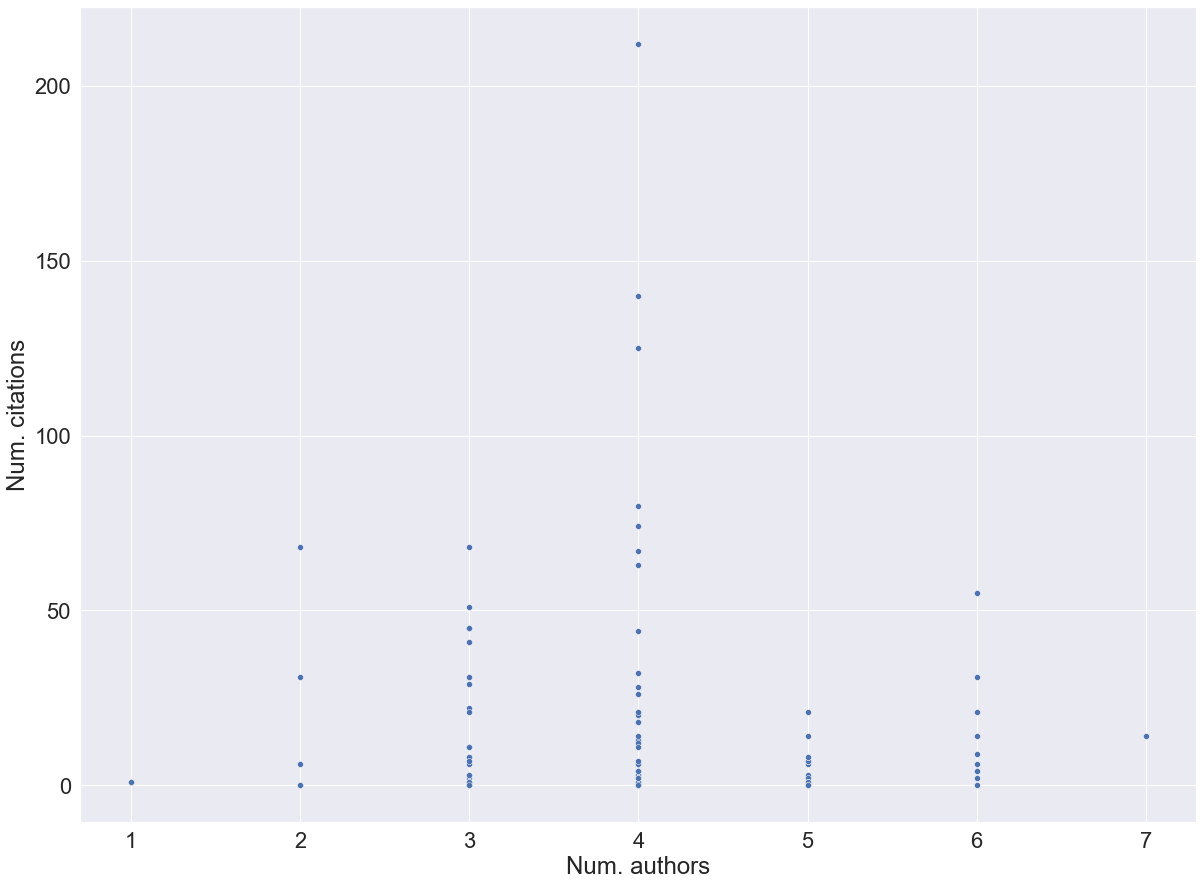
m,b = np.polyfit(final_list_citation, final_list_impact, 1)
plt.scatter(final_list_citation, final_list_impact)
plt.ylabel("Impact score")
plt.xlabel("Citation score")
x = np.arange(0, 200)
plt.plot(x, m*x +b)
plt.title("Relationship between citation score and impact score")
print("Gradient of best fit line {}, intercept of best fit line {}".format(m, b))## Gradient of best fit line 0.04122799891846959, intercept of best fit line 1.0437023459340433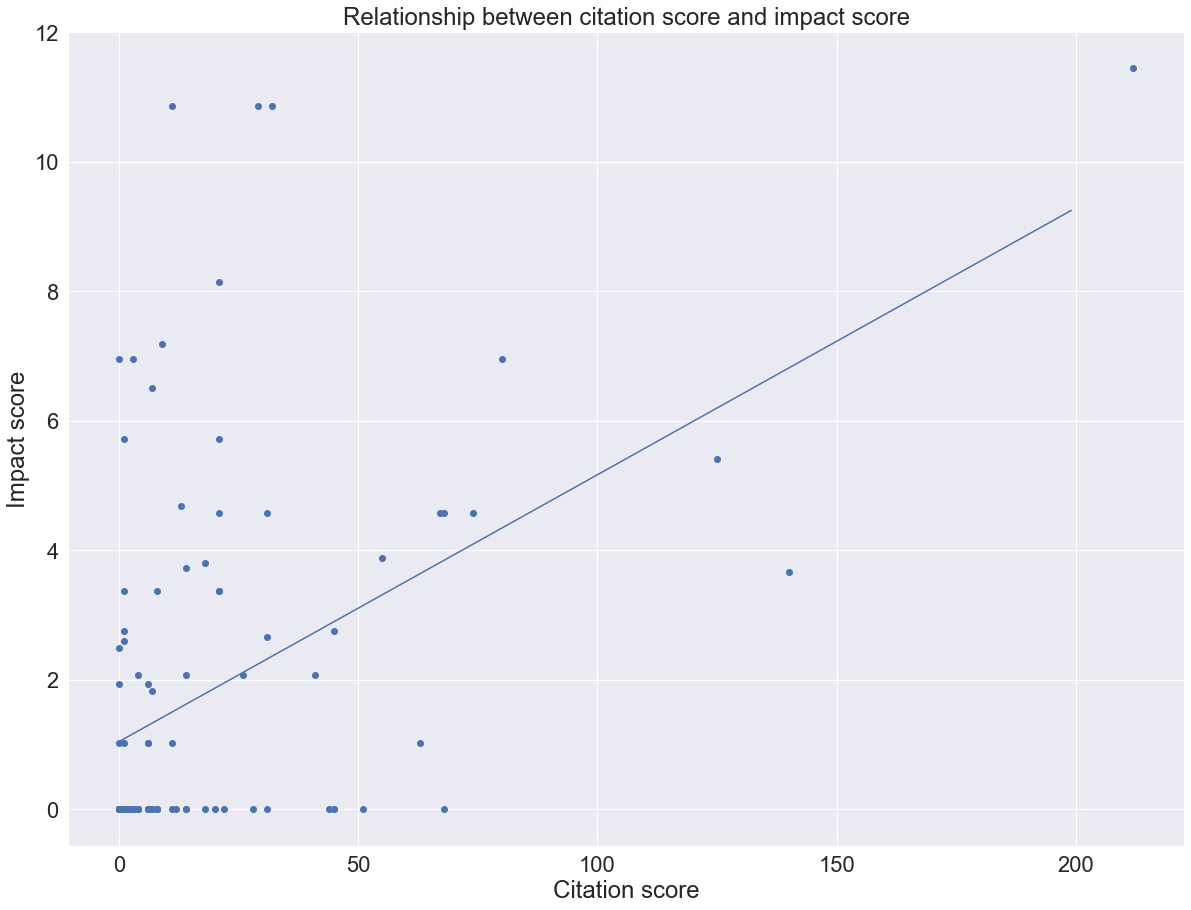
## length of the abstract
length_of_abstract = [len(item['abstract'].split(" ")) for item in text_data_list]
m,b = np.polyfit(length_of_abstract, final_list_citation, 1)
plt.scatter(length_of_abstract, final_list_citation)
plt.xlabel("length abstract (words)")
plt.ylabel("Citation score")
x = np.arange(60, 300)
plt.plot(x, m*x +b)
plt.title("Relationship between length of abstract and citation score")
print("Gradient of best fit line {}, intercept of best fit line {}".format(m, b))## Gradient of best fit line 0.08190776180347488, intercept of best fit line 1.8387600671150923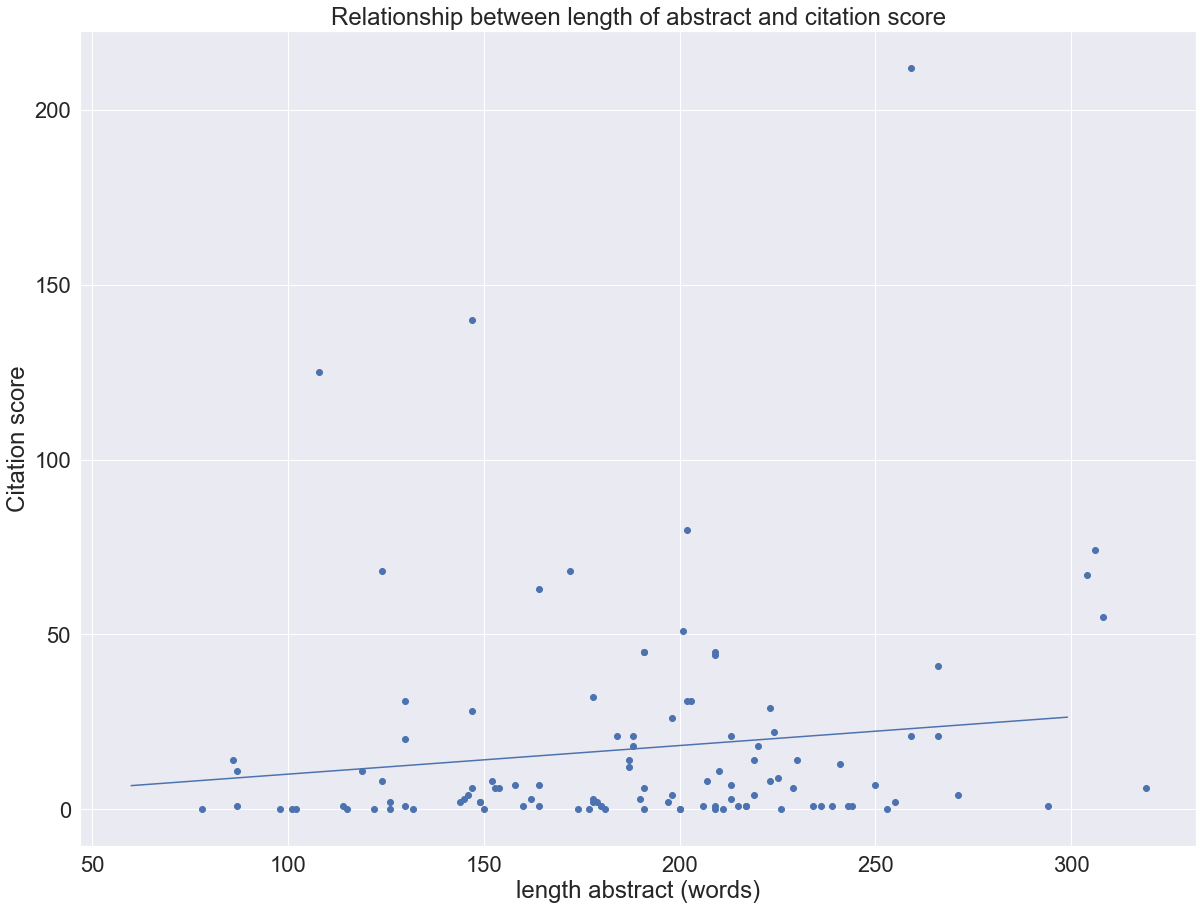
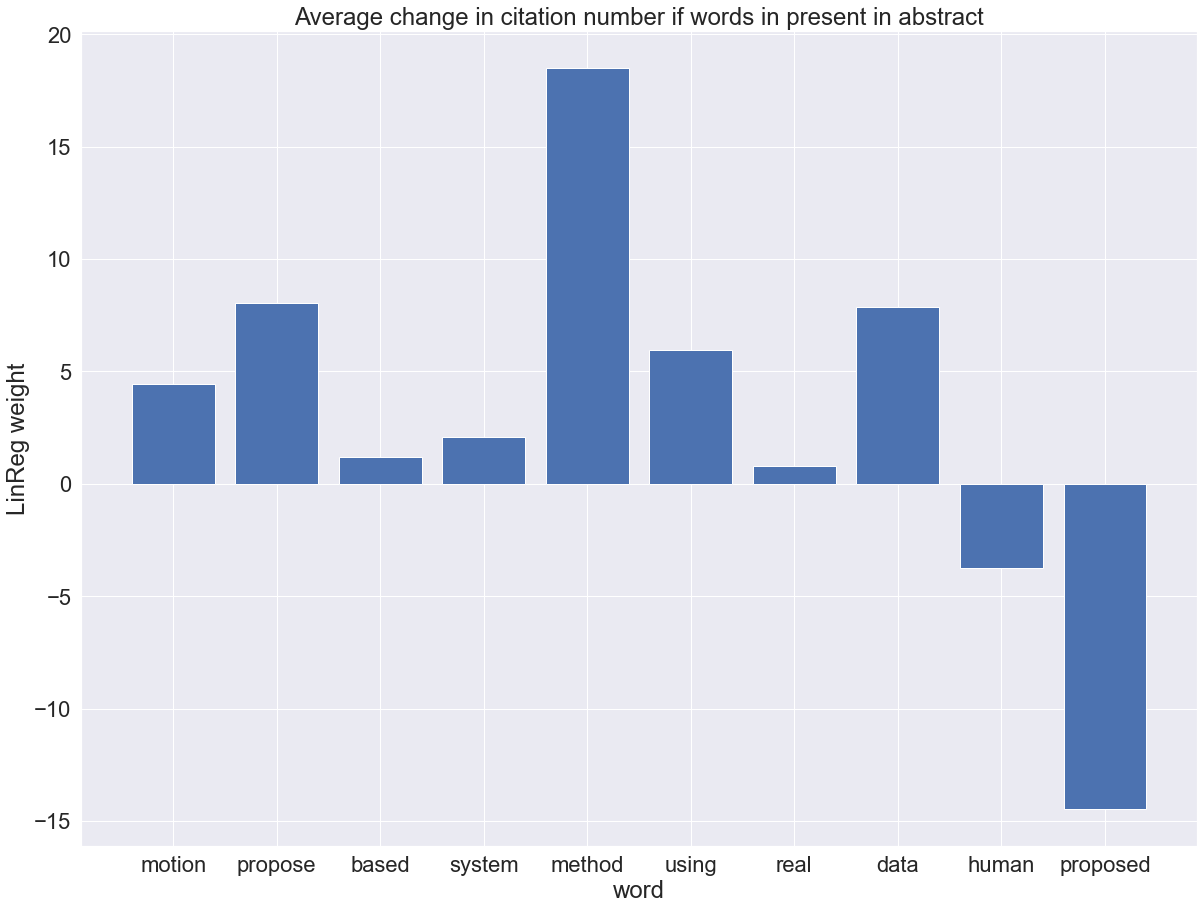
X = 10
words = abstract_popular_words[:X]
words## ['motion', 'propose', 'based', 'system', 'method', 'using', 'real', 'data', 'human', 'proposed']def convert_paper_to_array(data, words):
inds =[ind for ind, word in enumerate(words) if word in data['abstract']]
array = np.zeros(len(words))
array[inds] = 1
return array
X = np.array([convert_paper_to_array(item, words) for item in text_data_list])
from sklearn.linear_model import LinearRegression
reg = LinearRegression().fit(X, final_list_citation)
reg.intercept_## -4.98099150459732reg.coef_## array([ 4.42700816, 8.03778339, 1.1806539 , 2.06893989,
## 18.50784099, 5.97331319, 0.81146567, 7.867291 ,
## -3.72320421, -14.47094619])for weight, word in zip(reg.coef_, words):
print("Word: {}, LinReg weight: {}".format(word, weight))## Word: motion, LinReg weight: 4.427008155697389
## Word: propose, LinReg weight: 8.03778338979055
## Word: based, LinReg weight: 1.1806539033384895
## Word: system, LinReg weight: 2.068939890399175
## Word: method, LinReg weight: 18.50784098635962
## Word: using, LinReg weight: 5.973313194749429
## Word: real, LinReg weight: 0.811465674346331
## Word: data, LinReg weight: 7.867291001488287
## Word: human, LinReg weight: -3.723204213088263
## Word: proposed, LinReg weight: -14.47094619340461print("\nLinReg weight represents the average increase in citations if the word is present in the abstract")##
## LinReg weight represents the average increase in citations if the word is present in the abstractplt.bar(x=words, height=reg.coef_)## <BarContainer object of 10 artists>plt.title("Average change in citation number if words in present in abstract")
plt.xlabel("word")
plt.ylabel("LinReg weight")